
Why We Do Test Automation

When I first started automating tests, I didn’t have a strong reason for it. Every mature QA team seemed to do it, job postings asked for it, and honestly, watching a dozen browsers open in parallel and run through test cases on their own looked really cool. That was mostly it.
I knew I was saving time. But I wasn’t fully confident in the results. I’d run the suite and then go double-check the important stuff manually anyway, just in case. The automation was doing something, I just wasn’t sure how much I trusted it yet.
That changed.
What Automation Actually Is
Before I get into when it clicked for me, it’s worth being clear about what automation actually does, because it’s simpler than people make it sound.
Automation is just testing done by a machine instead of you. That’s it.
Take a login test. Manually, you navigate to the page, type your credentials, click submit, and check that you landed on the right screen. To automate that, you need a tool that can perform those same steps without you sitting there doing them. Tools like Playwright, Selenium, and Cypress exist specifically for this. They control a browser the same way you would, just faster and without getting bored.
The test itself is the same. The steps are the same. The only difference is who’s running them.
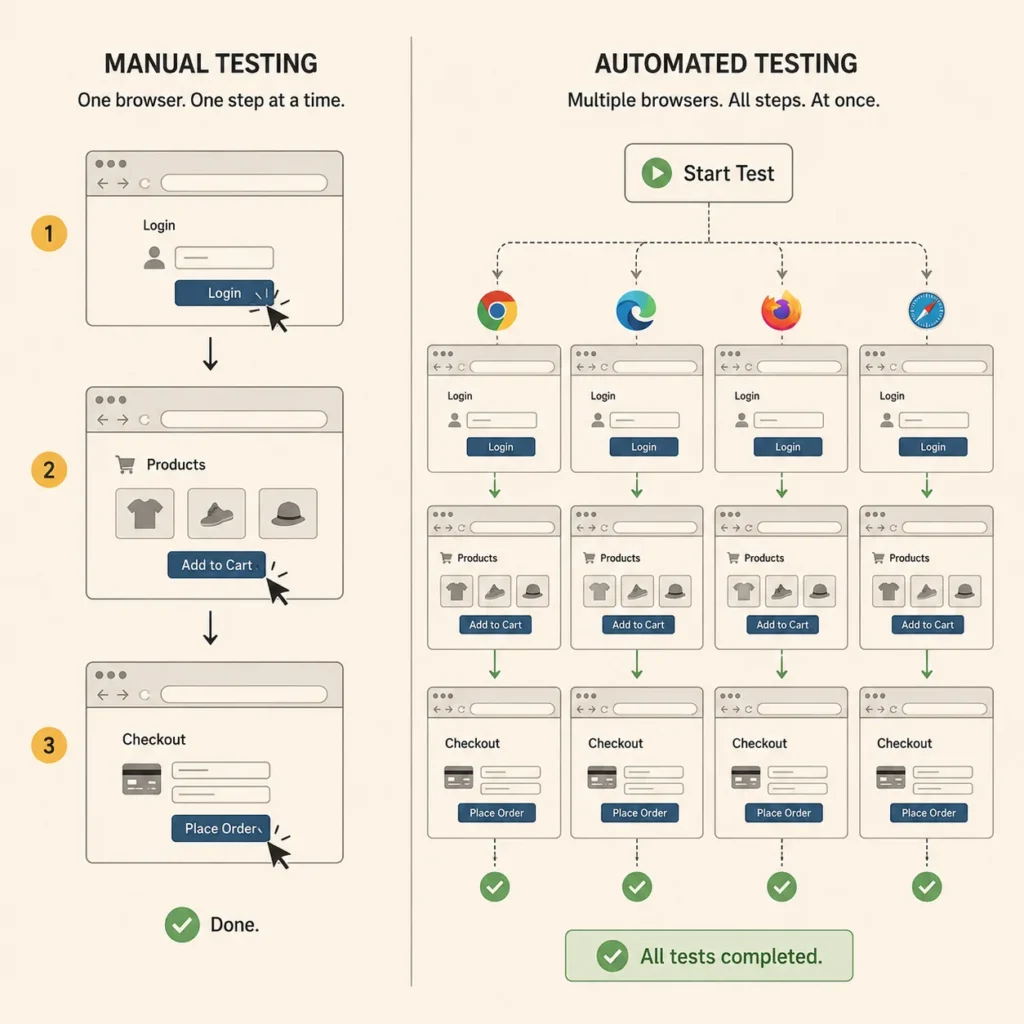
Why You’d Bother
The honest answer is that you’re human and humans aren’t built for repetitive precision work at scale.
For a single login test, you’re fine. You’re fast, you’re accurate, you don’t need automation. But QA isn’t one test. It’s hundreds of them, run repeatedly, sprint after sprint. And somewhere around the fiftieth time you’ve manually checked the same regression scenarios, you start glossing over things. We get tired. We get distracted. We want to clock out.
A machine running that same test for the five hundredth time is just as thorough as it was on the first run. It doesn’t cut corners. It doesn’t skip the assertion at the end because it’s 4:45pm on a Friday.
Speed is the other thing. Automated tests run fast, and they can run in parallel. What takes you a few hours to check manually can finish in minutes. I think of my automated suite as a team of testers running alongside me. They handle the boring, predictable regression work while I focus on the things that actually need a human brain.
When It Stopped Being a Novelty
There were so many times I didn’t trust an automated test failure, ignored it, and turned out I was wrong. Or I’d find a bug and ask myself why the test passed. Each time I went to debug it, I’d realize I hadn’t asserted enough — or that the test had actually picked up a subtle but real bug, one that was only reproducible at the speed an automated test runs at.
I’ve been wrong so many times that I just get embarrassed I doubted and just trust my tests now.
It was also especially satisfying when the suite caught a critical bug in the checkout flow that my teammates missed because they skipped the regression that had been set up to run manually.
That’s when the confidence thing finally made sense to me. It wasn’t about the technology. It was about repetition. I’d run these tests hundreds of times. I knew exactly what they checked, because I wrote them. I knew what a failure meant, because I’d seen failures before and investigated them. At a certain point the results stopped being data I had to interpret and started being something I just trusted.
That trust doesn’t come automatically though. It gets built the same way any trust does — over time, through consistency. An automated suite you’ve been running for two weeks isn’t the same as one you’ve been running for a year.
The Part I’m Still Figuring Out
There’s a push in a lot of teams to automate within the sprint — write the automated tests at the same time you’re building and testing the feature. In theory this makes sense. In practice I’m not convinced yet.
My concern is maintenance. Automating a new feature mid-sprint means writing new test code against a UI that might still be changing. One design tweak and half your new tests need to be rewritten. Unless your suite is already mature enough that you have reusable pieces to build from, you’re probably adding more work than you’re saving.
If you’re going to try in-sprint automation, my gut says keep it to the happy path of the new feature and nothing more. Save the edge cases and complex scenarios for when the feature is stable. And make sure you actually have the capacity. You’re still doing all the manual preventative work during design and implementation, plus the actual testing when the ticket lands in QA. Squeezing automation on top of that without extra time or resources is a good way to do all three things poorly.
I haven’t landed on a firm answer here. It depends on the team, the suite maturity, and how stable your product tends to be. But I’m skeptical of anyone who tells you in-sprint automation is straightforward.
So Should You Automate?
Yes. Absolutely.
But go in knowing that the value compounds over time. The first few weeks of your suite existing, you’ll second-guess it. That’s normal. Run it anyway. Fix the flaky tests. Add assertions wherever you catch yourself wanting to double-check something manually. Over time you’ll stop watching it run and start trusting what it tells you.
That’s the point you’re building toward. Not cool parallel browsers — though that part is still pretty neat.